
Overview
The Deduplicated File System section shows information about your UCAR garbage collection system.
For clients using deduplication, the UCAR system runs a garbage collection process every day to find and purge any files that are no longer referenced.
Some ways that data can become the non-referenced garbage are when clients are deleted without their jobs being purged or when old jobs were not removed completely. It is recommended to run garbage collection after deleting jobs to insure the data is cleared completely. This is similar to the jobs with the non-referenced data. (See Unreferenced Data.)
The garbage collection will be deferred for up to 12 hours before it terminates the process. If the process times out, it will be retried at its next regular time. There is one exception. In the event the system is running low on space, the garbage collection will proceed if there are jobs deduplicating or not.
Unique Content-Addressable Repository

| Name | Description |
|---|---|
| Garbage Collection | Start the garbage collection |
| Garbage Collection Time of Day | Set the time of day when the garbage collection will run automatically |
| Compact Online | Start Online DDFS Compact manually |
| Verify UCAR | Verify the UCAR integrity. This will systematically read all the files in UCAR, and verify if their computed signature matches the recorded one. If not, the file will be quarantined. The process is extremely I/O intensive and can take weeks to run to completion on systems with large amount of the stored data. Use only when told by the Infrascale Support. |
| Request Missing Blocks | Request and upload the replicated data blocks missing on the appliance |
This group shows the following real-time processing data:
| Data | Description |
|---|---|
| Total UCAR Bytes | |
| Processed Files | |
| Processed Bytes | |
| Duplicate Files | |
| Duplicate Bytes | |
| Quarantined Bytes | |
| Quarantined Files |
Garbage Collection History
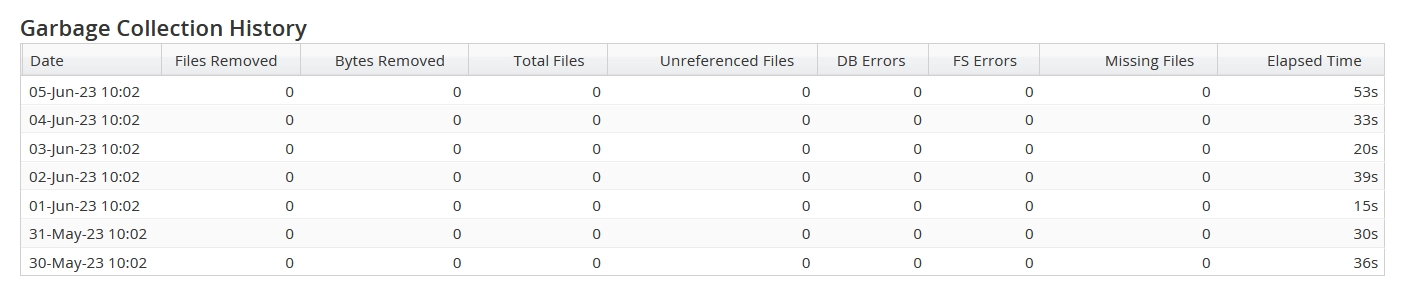
This group shows the following data:
| Column | Description |
|---|---|
| Date | Date of processing |
| Files Removed | Number of files removed |
| Bytes Removed | Number of bytes removed |
| Total Files | Total number of unique files |
| Unreferenced Files | Number of files found in UCAR, but not in the database |
| DB Errors | Number of the database errors encountered while processing |
| FS Errors | Number of the file system errors encountered while processing |
| Missing Files | Number of files referenced by backups, but not present in UCAR |
| Elapsed Time | Total processing time |
Block Deduplication
Block Deduplication Statistics
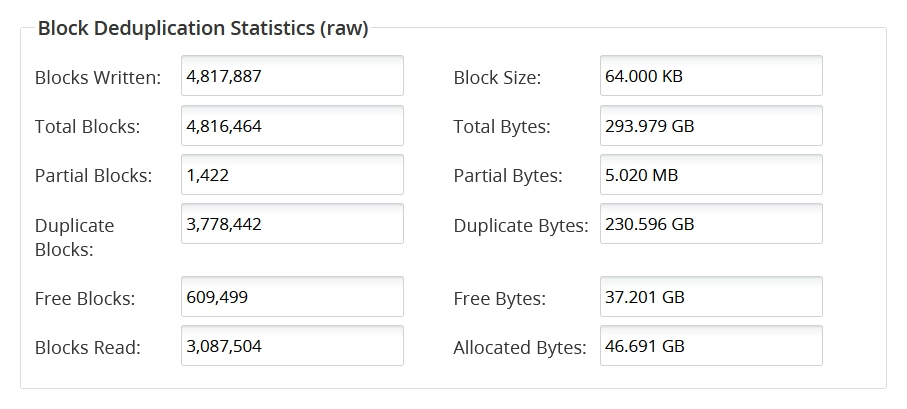
This group shows the following data:
| Data | Description |
|---|---|
| Blocks Written | Total number of full blocks that have been written into DDFS since it was configured initially |
| Block Size | The size of the blocks files are divided into during the deduplication process. This option is not configurable. |
| Total Blocks | The total number of blocks that have been written to DDFS since it was configured initially. It includes both full and partial blocks. |
| Total Bytes | The number of partial blocks that have been written to DDFS since it was configured initially |
| Partial Blocks | The total of the size of all the partial blocks that have been written to DDFS. Partial blocks happen at the end of a file that does not evenly divide into blocks. For example, a 96 kB file will be divided into 64 kB full block, and 32 kB partial block. |
| Partial Bytes | The number of times a block already existed in the block store and did not need to be written again, thus saving space |
| Duplicate Blocks | The number of bytes that did not have to get written to the RAID because we already had a copy of a block |
| Duplicate Bytes | The sum of the size of all of the blocks marked as free in the block store |
| Free Blocks | A counter of times blocks have been read back from the DDFS |
| Free Bytes | The sum of the size of all of the blocks marked as free in the block store |
| Blocks Read | A counter of times blocks have been read back from the DDFS |
| Allocated Bytes | The size of the block stores. Includes both the used and the free blocks. |
Shredder Statistics
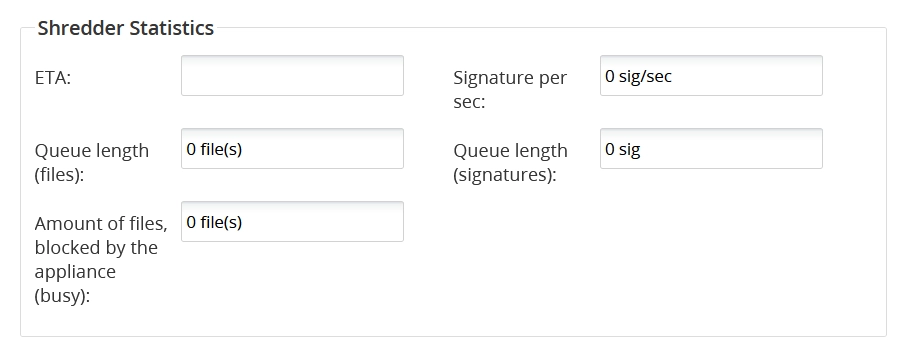
This group shows the following data:
| Data | Description |
|---|---|
| ETA | |
| Signature per sec | |
| Queue length (files) | |
| Queue length (signatures) | |
| The current file being processed | |
| Amount of files, blocked by the appliance (busy) |
Block Address Map Statistics
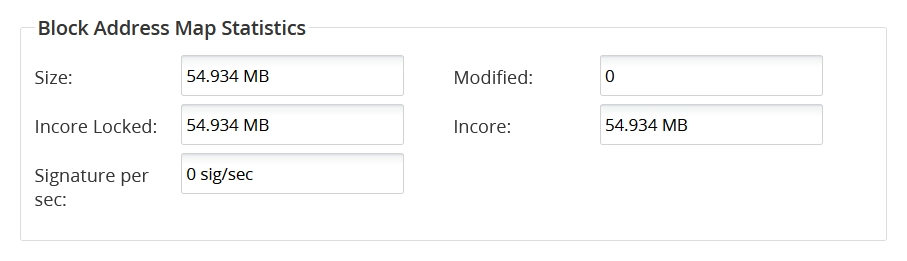
This group shows the following data:
| Data | Description |
|---|---|
| Size | |
| Modified | |
| Incore Locked | |
| Incore | |
| Signature per sec |
App Statistics
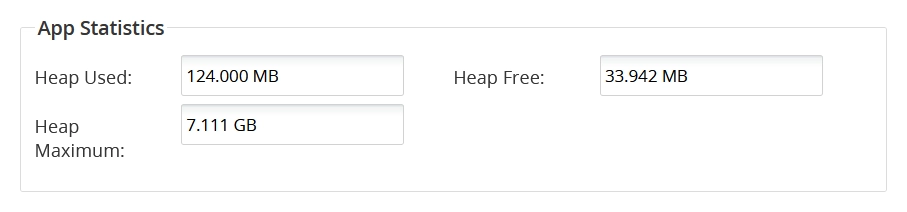
This group shows the following data:
| Data | Description |
|---|---|
| Heap Used | |
| Heap Free | |
| Heap Maximum |